Are you grappling with the complexities of managing data streams from your IoT devices? Understanding and effectively implementing remote IoT batch jobs can revolutionize your approach, streamlining processes and unlocking unprecedented efficiency.
The digital landscape is rapidly evolving, and with it, the need for robust and efficient data management solutions. For those immersed in the realm of AWS remote IoT, the setup of batch jobs can initially appear daunting. However, the core principle remains straightforward: organizing a comprehensive cleanup of your digital footprint. This process involves meticulously sorting, processing, and analyzing vast amounts of data collected from a myriad of IoT devices, which ultimately allows for better decision-making and optimized operational performance. Whether you're a developer, system administrator, or business owner, the ability to harness the full potential of remote IoT batch jobs is becoming increasingly critical.
Let's delve into the essentials of AWS remote IoT batch jobs, particularly focusing on scenarios where tasks have been running remotely for an extended period. This deep dive ensures you're equipped with actionable insights and proven best practices. This isn't merely about adopting a new technology; it's about fundamentally altering how you interact with and leverage your data.
Not all batch job setups are created equal. The journey of optimizing your current setup or starting from scratch hinges on a thorough comprehension of remote IoT batch jobs. This article will equip you with the fundamental knowledge to confidently navigate this landscape.
Remote IoT batch jobs on AWS are not simply a buzzword; they represent a powerful solution for automating repetitive tasks while effectively managing IoT devices. The essence of a remote IoT batch job is a process designed to handle enormous quantities of data gathered from IoT devices in a scheduled or automated way. Imagine it as a high-speed sorting mechanism for the lifeblood of your smart systems.
This comprehensive guide delves into the intricacies of remote batch job processing in IoT systems, providing actionable insights for both beginners and experts alike. Consider it your personal roadmap to mastering this critical area.
We will break down the implementation process, making it accessible regardless of your current technical expertise. The aim is to turn what may seem like a complex undertaking into a walk in the park, providing you with the tools and knowledge to succeed.
Whether you are building a sophisticated smart home system, managing intricate industrial IoT deployments, or involved in any other application, the value of mastering remote IoT batch jobs on AWS is substantial. It streamlines data processing, optimizes resource usage, and supports better decision-making driven by real-time insights.
To provide a structured understanding, we will examine the core components, best practices, and real-world examples. Throughout this exploration, you will uncover effective methods for implementation, troubleshooting, and optimization. From basic concepts to more advanced topics, this guide will equip you with the skills necessary to leverage remote IoT batch jobs effectively.
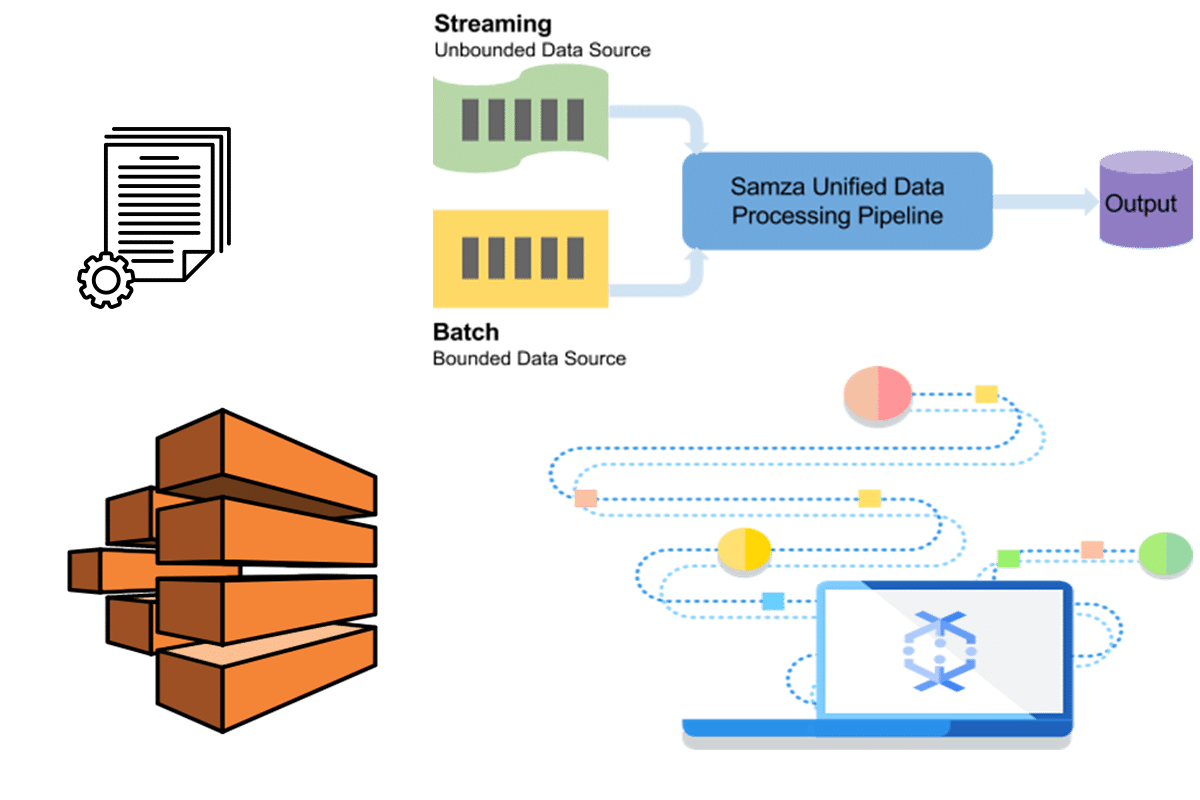
Let's explore the critical elements that constitute a remote IoT batch job. First, there are data sources. These are the origins of your data, typically IoT devices, such as sensors, devices, or equipment. Data is generated and transmitted to a central location where batch jobs process it.
The next element is the data ingestion process. Data needs to be collected, transported, and stored in a manner that is accessible for batch processing. This may involve protocols such as MQTT, HTTP, or other specialized IoT communication techniques. AWS services such as AWS IoT Core, Kinesis, and S3 often handle the ingestion process, providing the scalable infrastructure needed to deal with the volume and variety of data from your IoT devices.
Then there's data storage. This involves selecting the right database and storage solutions. Options include Amazon S3 for storing raw data, Amazon DynamoDB for structured data, and data lakes and data warehouses for long-term analysis. Proper storage and retrieval strategies are critical for efficient processing and data analysis.
Data processing and transformation is the core of any batch job. This is where the real work takes place. Batch jobs transform raw data into a format that is accessible and actionable, including cleansing, filtering, and aggregating data. Common tools include AWS Lambda, Amazon EMR, and Apache Spark. The processing step prepares the data for analysis and helps to make it useful.
Job scheduling and orchestration is essential. Batch jobs need to be scheduled to run at specific times or in response to certain events. AWS Step Functions, CloudWatch Events, and other scheduling services give you granular control over job execution. Good orchestration guarantees data is processed accurately and efficiently.
Monitoring and logging are crucial for maintaining the health and efficiency of your batch jobs. Monitoring involves tracking job execution, identifying errors, and measuring performance. AWS CloudWatch provides comprehensive monitoring tools. Logging lets you record events, errors, and performance metrics to help with troubleshooting and analysis. Proper monitoring and logging help ensure that the batch jobs run as planned and provide valuable data.
Finally, data analysis and output provide insight and usability. Data is then analyzed to generate reports, insights, or other outputs. Tools such as Amazon Athena, QuickSight, and machine learning models can convert raw data into actionable insights. The final output informs decision-making and improves system performance.
Batch processing is essential to managing vast amounts of data collected by IoT devices. To fully understand how to implement a remote IoT batch job example, let's walk through a practical scenario.
Imagine a smart agricultural system with numerous sensors deployed across a large farm. These sensors gather real-time data on environmental conditions like soil moisture, temperature, and humidity. This data gets transmitted to AWS IoT Core. Using AWS IoT Rules Engine, the data is then sent to a Kinesis data stream for real-time processing and another copy of data goes to Amazon S3 for long-term storage.
A batch job, triggered by an event scheduled using CloudWatch Events or run on a predefined schedule, uses AWS Lambda to collect data from the S3 bucket. This is where the data transformation and processing phase starts. The batch job aggregates the sensor data on a daily basis, calculating the average moisture levels, temperature fluctuations, and other key metrics for each field.
Once the data is processed, the output is stored in Amazon DynamoDB, which allows for easy retrieval by field managers. The system then generates reports or alerts based on the analyzed data using Amazon QuickSight. These reports help farmers make informed decisions about irrigation, fertilization, and other critical farm operations.
The benefits of this system are multi-fold. It allows farmers to optimize their resource usage, increase crop yields, and lower operational costs. Continuous monitoring and real-time data-driven insights provide an effective method for enhancing agricultural operations.
Consider a different scenario: a smart home system. The system has many IoT devices, including smart thermostats, door locks, and security cameras. These devices generate data about the home's environment and security. This data is transmitted to AWS IoT Core. AWS IoT Rules Engine is used to store the raw data in Amazon S3, and the processed data is sent to Amazon DynamoDB.
A batch job, scheduled to run every night using CloudWatch Events, collects data from Amazon S3. The Lambda function aggregates all of the data collected from devices each day, such as the average temperature settings for the thermostat and the number of times the door locks were used. It also examines patterns in the security camera data for suspicious activity.
The insights gained are then saved to Amazon DynamoDB and can be visualized in a customized dashboard using Amazon QuickSight. This data enables homeowners to monitor their energy consumption, improve home security, and better understand their home environment. It also provides insights into the usage of household appliances and device performance.
The implementation of remote IoT batch jobs requires strategic planning, careful consideration, and an understanding of best practices. Let's look at some key areas.
Firstly, establish clear objectives. Begin by defining the precise outcomes you want to accomplish with your batch jobs. Determine the data you intend to process, the frequency of processing, and the desired outcomes. Clearly defined goals will guide your design choices.
Then comes the data collection and ingestion strategy. Select efficient and reliable methods for data collection. Choose protocols and services that fit your IoT devices' requirements, the volume of data, and the required latency. Be sure that the ingestion pipeline is scalable and can deal with the volume of data from your devices.
Next, design the processing pipeline. This is a very critical process. Design your batch processing workflow to optimize speed and efficiency. Consider partitioning the data, parallel processing, and using appropriate compute resources such as AWS Lambda, Amazon EMR, and containerized solutions such as Amazon ECS or Kubernetes to ensure optimal performance. Optimize the processing logic to reduce latency and resource consumption.
Focus on the data storage solution. Select storage solutions that meet your needs for scalability, durability, and cost-effectiveness. For instance, use Amazon S3 for the long-term storage of raw data, and Amazon DynamoDB for structured data access, or Amazon Redshift for analytical data. Ensure your storage strategies align with data lifecycle management, including data retention, archiving, and deletion policies.
Then, consider job scheduling and monitoring. Implement a robust job scheduling system using AWS CloudWatch Events or Step Functions to automate job execution. Also, integrate thorough monitoring and logging using CloudWatch to proactively monitor job performance, spot errors, and optimize efficiency. Use these insights to proactively deal with performance and operational problems.
Implement thorough security measures. Secure your entire system, including the data ingestion process, storage, and processing layers. Implement access controls, encryption, and other security measures to prevent unauthorized access. Keep up with security best practices and regulations.
Lastly, be sure that you test, test, and test. Before implementing batch jobs in production, thoroughly test your implementation to ensure that everything works as expected. Test the pipeline's performance, scalability, and fault tolerance to detect and solve possible problems. Use thorough testing as a core component of your implementation process.
Building and effectively implementing remote IoT batch processing often requires more than just technical expertise; it needs a strategic view of how your data can create value. Consider the benefits of data governance, data quality, and compliance with industry standards.
Data governance ensures the integrity and proper management of your data. It entails setting policies, processes, and standards to manage the quality, security, and access of your data. Good data governance includes clear data ownership and responsibility, as well as data lineage and metadata management.
Data quality is essential. Data quality directly affects the accuracy and reliability of the insights obtained from the data. Implement data validation, cleaning, and standardization processes as part of your batch jobs. This will help ensure that the data used is correct, complete, and consistent.
Regulatory compliance is critical. Your batch jobs should comply with industry-specific standards such as GDPR, HIPAA, or other regulations. Understand and implement the appropriate compliance requirements such as data privacy, security, and data retention policies. Data protection is very important to regulatory compliance.
Let's consider advanced techniques that can optimize your remote IoT batch processing. This includes approaches like edge computing, data partitioning, and advanced data analytics.
Edge computing lets you process data closer to where it's generated, decreasing latency and reducing the load on your central processing systems. This will improve the responsiveness of applications and increase the efficiency of data transfer by pre-processing some of the data at the edge of the network. This also increases the security of your system because sensitive data remains on the device or within a local network.
Data partitioning involves dividing large datasets into smaller, more manageable segments. Partitioning improves the efficiency of the data processing by allowing parallel processing, thus reducing the overall processing time. Use the most appropriate partitioning method based on data characteristics, data access patterns, and specific use cases to optimize your systems performance.
Advanced data analytics, including machine learning and artificial intelligence, enables better insights and improved decision-making. This can be done by applying predictive analytics, anomaly detection, and other machine-learning techniques. For example, use machine learning models to predict device failures or develop anomaly detection systems to identify unusual patterns in your data. This helps generate actionable insights and optimize the efficiency and effectiveness of your IoT solutions.
Troubleshooting remote IoT batch jobs requires a systematic approach. One of the best ways to do this is through detailed logs and comprehensive monitoring. The following are key steps.
Firstly, inspect job logs. Dive deep into the job execution logs. The logs will include detailed information on the steps taken, including any errors encountered. Use cloud services such as Amazon CloudWatch Logs or other logging tools to identify specific error messages, understand the root causes, and track down any issues.
Then, use the monitoring tools. Monitor resource usage, job status, and processing times. CloudWatch can provide real-time metrics and alerts. This is useful for identifying bottlenecks, unexpected performance declines, and other operational issues.
Check data pipelines. Investigate the entire data pipeline, including data ingestion, transformation, and storage. Verify data is being ingested as expected, transformed as needed, and stored correctly. Incomplete or inaccurate data may indicate issues with the data collection process, data transformation logic, or data storage configuration.
Conduct resource analysis. Review the resource usage of your batch jobs, including CPU utilization, memory consumption, and network I/O. If resources are underutilized or over-consumed, you can then adjust the allocated resources accordingly. Adjustments can help in improving job performance and reducing unnecessary costs.
Then, investigate security measures. Review access controls, data encryption, and network configurations. Improper security configurations could lead to job failures or data breaches. Make sure that your security configurations are implemented securely. You can also perform regular security assessments to determine any weaknesses.
Review the configuration and dependencies. Verify your configuration parameters. For example, configurations of services, access rights, environment variables, and dependent services. Incorrect configuration settings or dependencies are often the source of job failures. Test any changes to your configuration parameters to identify and fix potential problems.
Finally, test, iterate, and implement. Repeat the process until the issues are solved. Once a problem is identified, make the necessary adjustments, retest the batch jobs, and verify they are running as expected. Use this continuous iteration to optimize your jobs for performance and dependability.
Mastering remote IoT batch processing gives you the ability to manage and analyze vast quantities of data from IoT devices. By following these best practices and understanding the tools available, you'll be well on your way to creating efficient and effective batch processing systems. With careful planning and constant monitoring, your batch jobs will transform raw data into actionable insights.

Detail Author:
- Name : Stephania Graham
- Email : nienow.emma@douglas.biz
- Birthdate : 1976-01-04
- Address : 1367 McKenzie Union Keltonland, OH 58872
- Phone : 240-828-7898
- Company : Larson Group
- Job : Correspondence Clerk
- Bio : Alias aperiam ea hic delectus earum ut. Molestias nesciunt ab tenetur non ut nulla aspernatur. Rem rerum omnis placeat modi. Qui vero aspernatur nostrum sapiente aut occaecati.
